什么是爬虫?
wiki是这么解释的:
是一种“自动化浏览网络”的程序,或者说是一种网络机器人。它们被广泛用于互联网搜索引擎或其他类似网站,以获取或更新这些网站的内容和检索方式。它们可以自动采集所有其能够访问到的页面内容,以供搜索引擎做进一步处理(分检整理下载的页面),而使得用户能更快的检索到他们需要的信息。
robots协议
robots.txt是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络爬虫),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
Robots.txt协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
说白了,这并不是一项需要强制遵守的规定,这只是一个君子之间的协议,防君子不防小人,但是不遵守这个协议可能导致不正当竞争,各位看官可以自行搜索下~
现简单列举下robots.txt中的一些配置规则,有个大致的印象,也有助于对爬虫逻辑的理解
- 允许所有机器人:User-agent: *
- 仅允许特定的机器人:User-agent: name_spider
- 拦截所有机器人:Disallow: /
- 禁止机器人访问特定的目录:Disallow: /images/
- …
反爬虫(Anti-Spider)
一般网站从三个方面反爬虫:
- 用户请求的Headers
- 用户行为
- 网站目录和数据加载方式
- …
前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
通过Headers反爬虫
很多网站通过检测Headers的:
- User-Agent
- Referer
反反爬虫策略:在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。
基于用户行为反爬虫
- 通过检测用户行为:
- 同一IP短时间内多次访问同一页面
- 同一账户短时间内多次进行相同操作
反反爬虫策略:1、专门写一个爬虫,爬取网上公开的代理ip,每请求几次更换一个ip;2、每次请求后随机间隔几秒再进行下一次请求
动态页面的反爬虫
上述的几种情况大多都是出现在静态页面,还有一部分网站,我们需要爬取的数据是通过ajax请求得到,或者通过JavaScript生成的
反反爬虫策略:找到ajax请求,也能分析出具体的参数和响应的具体含义,响应的json进行分析得到需要的数据。
需要预备的知识
- Javascript 及 JQuery
- 简单的nodejs基础
- http 网络抓包 和 URL 基础
对于前端工程师来讲真的是福利啊
需要安装的依赖库
- superagent
- cheerio
- eventproxy
- async
superagent
superagent 是个轻量的的 http 方面的库,是 nodejs 里一个非常方便的客户端请求代理模块,方便我们进行 get、post 等网络请求
[slide]
cheerio
可以理解成一个 Nodejs 版的 jQuery,用来从网页中以 css selector 获取数据,使用方式跟 jquery 一毛一样的。
eventproxy
eventproxy 模块是控制并发用的,它来帮你管理到底这些异步操作是否完成,有时我们需要同时发送 N 个 http 请求,然后利用得到的数据进行后期的处理工作, 请求完成之后,它会自动调用你提供的处理函数,并将抓取到的数据当参数传过来,方便处理。
async
async是一个流程控制工具包,提供了直接而强大的异步功能:mapLimit(arr, limit, iterator, callback)
还有强大的同步功能:
mapSeries(arr, iterator, callback)
爬虫实践
光说不练假把式,那么咱就开始吧~
先定义依赖库和全局变量~
|
|
|
|
三行代码~但这的确是一个爬虫程序,将页面信息输出到terminal~
因为要获取页面上的资源,而且要应用cheerio(node版的jQuery)来选择页面上指定class或者id中的内容,所以我们要先分析自己想获取页面的结构,打开google chrome的元素选择器,比如说现在我们只想获取cnode上每个词条点击的url。
将1中的程序加入cheerio获取urls:
|
|
输出: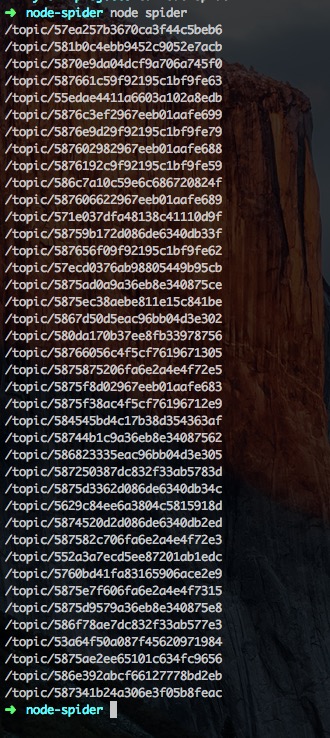
这都是相对路径呀,肿么办?别急,有url模块:
|
|
然后继续在执行程序输出: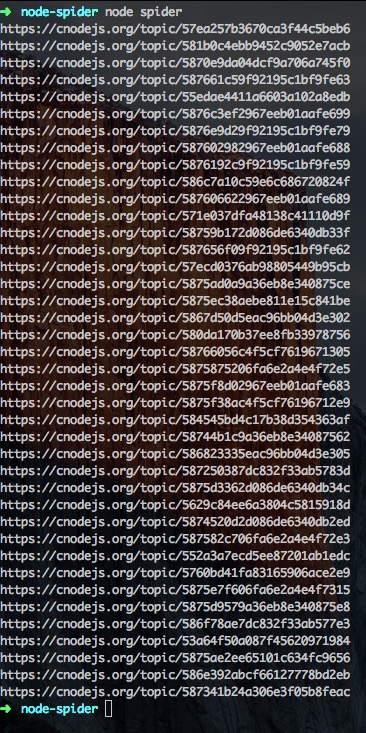
获取urls只是第一步,现在我们要获取把urls所指向的页面中的内容获取过来,比如说,我们要获取二级页面中的标题和第一个评论,然后打印出来。
这里我们要加入eventproxy模块来优雅地控制指定次数异步之后执行回调函数:
|
|
输出: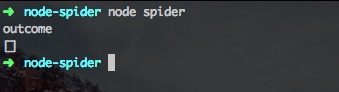
咦~这里outcome为空?什么鬼?我们又检查了下代码。shit!没有控制异步,导致执行topicUrls.forEach()的时候,topicUrls为空,当然是吗都没有,我们加入神器promise来改良下吧~
|
|
输出: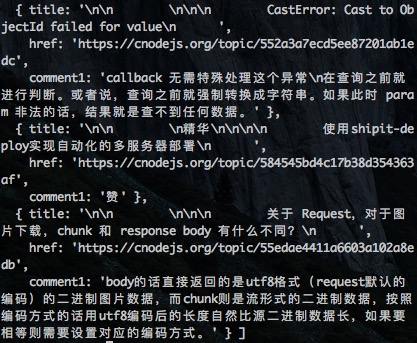
惊喜来了,页面上出现了我们希望出现的标题、url、和评论,但是有一点不符合预期,仔细观察输出日志,会有很多空的对象字符串: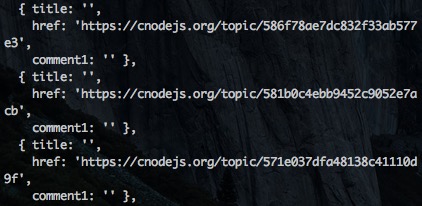
难道是页面不可访问?
我们复制这个没有输出的页面url到浏览器回车就回发现,页面其实是可以被访问的,因为在浏览器我们只是一次请求,而在爬虫程序中,因为node的高并发特性,我们在同一时间进行非常多次请求,如果超过服务器的负载,那么服务器就会崩溃,所以服务器一般都会有反爬虫的方法,而我们恰巧就遇到了这种情况,如何证明?我们直接输出urls所指向的所有页面(tips:因为terminal输出太多,可以使用linux命令|less来控制输出日志的分页翻页)
仔细观察输出,不久就会发现以下日志:
页面都是503,也就是服务器拒绝了我们的访问。
我们来改良下我们的程序,async登场,来控制程序的并发,并且设置延迟:
|
|
再看下输出日志: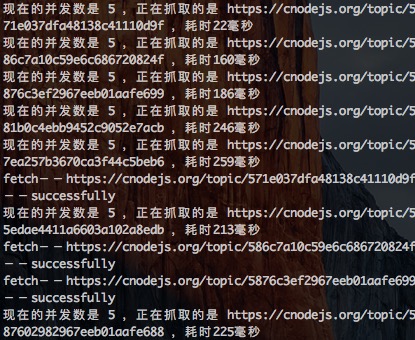
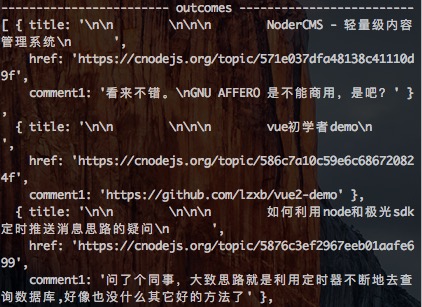
强迫症患者觉得很舒服有木有~
等等~还有一个重点没讲呢!对于诸多程序猿宅男来讲(此处省略万字),有了上面的基础,实现图片爬虫和储存也是很简单的额,比如说下载刚才讲的例子中的二级页面中的作者头像,分析页面的步骤就不多加描述了,直接上代码:
|
|
执行程序,然后你就会发现images文件夹下面多了很多图片了….嘿嘿嘿~